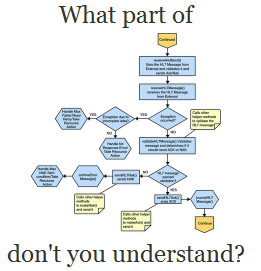
Someone asked me how to get started learning HL7v3 and I thought, hmmm...
I went looking for a simple definition, and the best I could find was from PC Magazine:
I went looking for a simple definition, and the best I could find was from PC Magazine:
(Health Level 7) ANSI-accredited standards for electronically defining clinical and administrative data in the healthcare industry from Health Level Seven International (www.hl7.org). HL7 provides standards for messaging, electronic records, decision support queries, medicine labels and the visual integration of data from different applications.Okay, so where to start.
The "7" in the name comes from application layer 7 in the OSI model, which is the highest level where programs talk to each other. HL7 does not deal with the lower levels of the OSI model, which are the transport and network protocols.
RIM
Reference Information Model. You can represent anything with this, all the basic building blocks organized by structure but not use case. It is typically implemented in XML, and can therefore be represented by an XML schema, or by a set of interfaces in an OO programming language.
The RIM can be thought of as the data and workflow model. The HL7 Standards Blog did a good brief description of this, and I would recommend reading their blog post, HL7 V3 RIM: Is it Really That Intimidating?
The RIM consists of actors, actions, relationships, roles, and entities. Everything happening in the course of care is an Act, and each Act may have any number of Participations, Roles, and Relationships between Entities. For another overview, see the HL7 Australia page on HL7 V3 Resources. Obviously this is as generalizable as possible, so to do useful things it is necessary to constrain the model in different ways, which leads us to the Clinical Document Architecture (CDA).
CDA
The standard for representing clinical documents using the all-purpose RIM. The Clinical Document Architecture ... the actual data structures we use in representing health information. Where the RIM represents structures, CDA organizes those structures into use cases. CDA R1 is finalized. R2 is not done yet. At least, the standard isn't finalized and is subject to change.
There are many standards documents within the CDA model, but they can be divided in two categories. There are the building blocks which define document components, and there are the documents themselves, which aggregate the components into complete clinical documents.
Two commonly used building blocks are C83 sections, and C80 code sets. Most clinical documents can be thought of as collections of C83 sections, with data encoded as prescribed by the corresponding C80 specification.
At the 2009 Connect Seminar, a simple diagram of the CDA standard relationships was given as part of a presentation. The full presentation may be downloaded from www.connectopensource.org (PowerPoint):

You can see the different types of documents
- C28 - Emergency Care Summary
- C32 - Summary Documents using HL7 Continuity of Care Document (CCD)
- C38 - Patient Level Quality Data Document
- C48 - Encounter Document
- C78 - Immunization Document
- C84 - Consult and History & Physical Note
There are many more types of documents, covering a wide range of use cases. A full list of the CDA document standards can be found on the HITSP Site. You can also see my earlier blog post about how CCDs are built.
Really, that's all you need to get started. Learn the RIM, choose the HITSP CDA documents applicable to your use case, and study the C83 sections and C80 codes needed. Then you're ready to get to work. Happy coding!























{kind=link}