Never before in human history has democracy had the tools available, where ordinary voters can so easily examine the workings of government in such detail. We are seeing the first few steps in a larger change in the fundamental way this information is managed.
Google Public Data Explorer launched February, 2011.
Tax day has come and gone and my dear old Uncle Sam and I have settled our accounts for another year. Everyone has an Uncle Sam, a nice old guy who doesn't manage his money so well so I help him out once in a while, just to, you know, make ends meet. You can't say no to Uncle Sam, with his white beard and stove pipe hat.
I don't know politics but I do know the Internet, which is full of crazy political rants. If you want to lose faith in humanity, just go to the Internet, find people who identify with a political party, and read what they writes about the other. Good times.
But hey, real issues, real money. What do I know?
What do I know just changed dramatically. Imagine if every dollar spent in the government, every receipt, every outlay, were recorded and place at my fingertips. What if I could chart all the government expenditures and revenues using any level of detail or axis of measure I choose?
You can get a taste of this with Google Public Data Viewer. It lets you mouse over the data, select, and change the perspective or data sets as fast as you want. The tools are here and only getting better. The only barrier now is getting everything concerning public policy into these data sets. In some ways, the process has been managed with all the bureaucratic efficiency one would expect, but what has been done is now rightfully mine to peruse and inform my vote. It's the citizens' data really, the taxpayers paid for it, and we own it. Let's take a look.
I decided to start with the phrase often heard lately: "We don't have a revenue problem, we have a spending problem." I bet if I can chart the various government expenditures, I'd agree with that. You can find the Federal Finances Dataset in the Google public data explorer Dataset Directory. I started with something simple: net outlays by year.

Yikes! It sure does look like we have a spending problem!. I also noticed how social security follows a relatively smooth upward curve, while the others have more little ups and downs. Everything's going up, except the few things everybody talks about cutting: science, education, agriculture, and energy - those programs behave the way I like my own budget, with a set price that doesn't go up every year.
Now what happens to those numbers if we compared them to the size of our economy? After all, we have more people, bigger cities, more jets, more of everything. So in terms of taking a percentage of our collective wages, what does our government look like?

Everything changes. Social Security isn't up nearly as much as I thought, the smaller programs are actually down, and the only thing that's really going up is health care. Maybe it is urgent, after all, maybe we should look at reform, as opposed to the plan I like to call repeal-and-replace-maybe-later-if-we-get-around-to-it.
Other than health care, really, the only spending problem we have is that we have to spend less and less every year. That's not how most people people like to manage their household finances, is it?
Now, how about those taxes? If we can prove we have a spending problem, we can conversely prove that we do not have a revenue problem, simply by charting the taxes with a few clicks of the mouse.

There's the revenue, and in terms of how big a piece of our pie it's around 20 percent, maybe less. I notice income tax - both personal and corporate - rise and fall relative to the state of the economy, while social security and the others (not shown here) have kept relatively steady. The peak revenue overall was 20% in 2000, which coincides with the peak budget surplus.
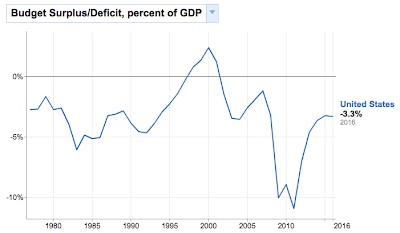

The point is, if I'm going to look at these issues and form opinions, let alone vote and try to convince others to vote with me, I better to do it with data. Whatever conclusions I ultimately reach, I'm going to know more with it than without it. That's probably the best I can do. Twitizen @abuaardvark once tweeted, "Sometimes I feel like the entire Internet is an exercise in documenting confirmation bias theory," or, as noted Wrongologist Kathryn Shulz points out, being wrong about something doesn't actually feel bad. It's only realizing you're wrong that feels bad.





{kind=link}